16-bit Carry Look-Ahead Adder
Overview
This 16-bit adder deviates from the standard adder implementation. The basic addition process is adding two numbers and then determining if there is a carry. This is called Ripple Carry addition, where the next digit operations depend on the completion of the previous digit. Carry Look-Ahead calculates all the carry operations at once, reducing computation time at the cost of power.
Quick Summary
-
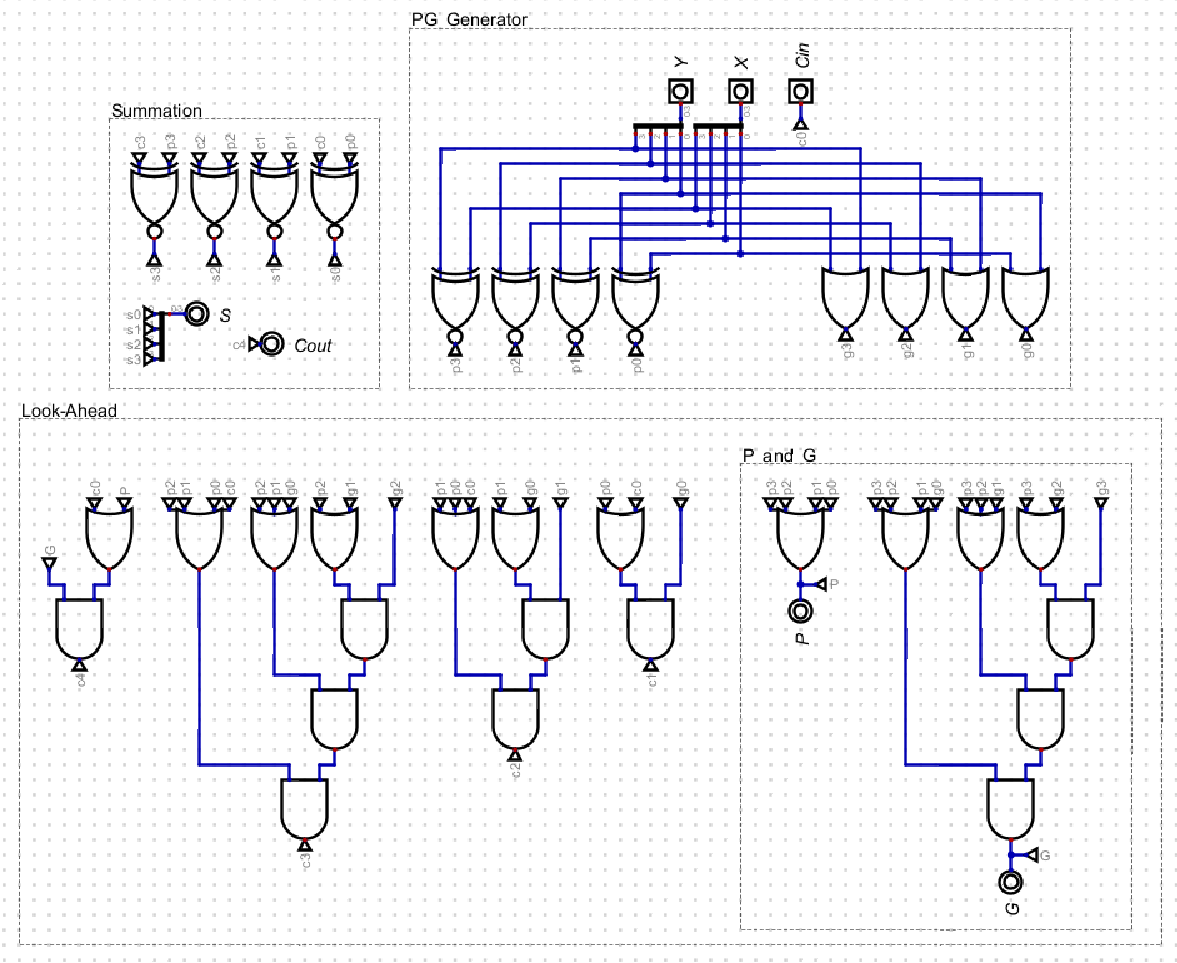
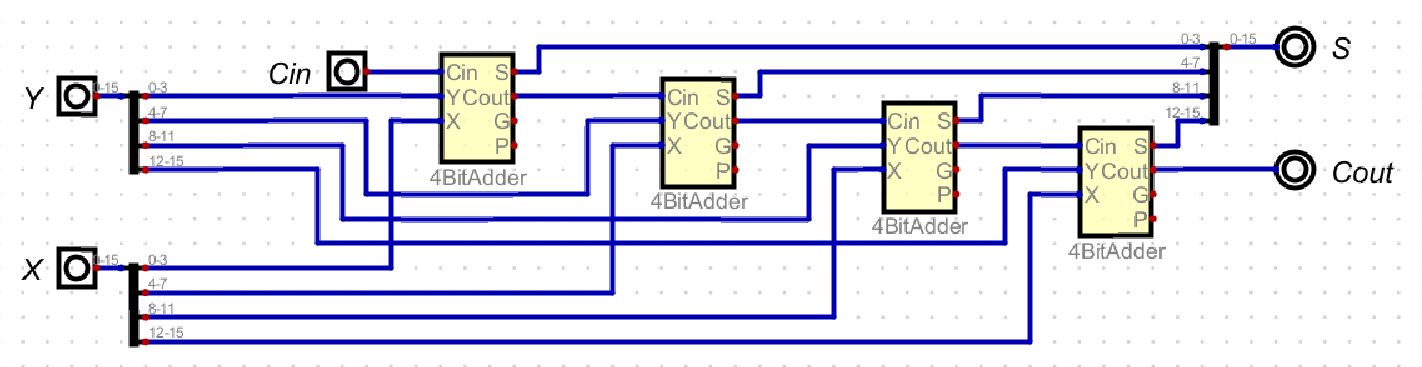
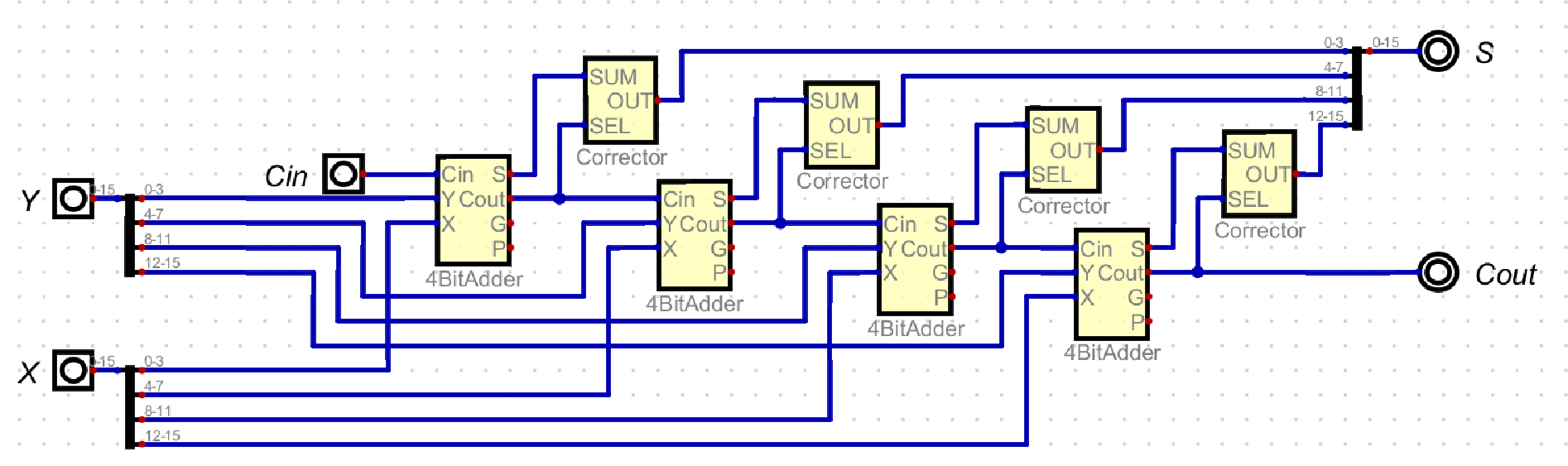
The Single Level CLA adder performs Carry Look-Ahead in 4 bit blocks and uses Ripple Carry addition to connect each 4 bit operation together.
-
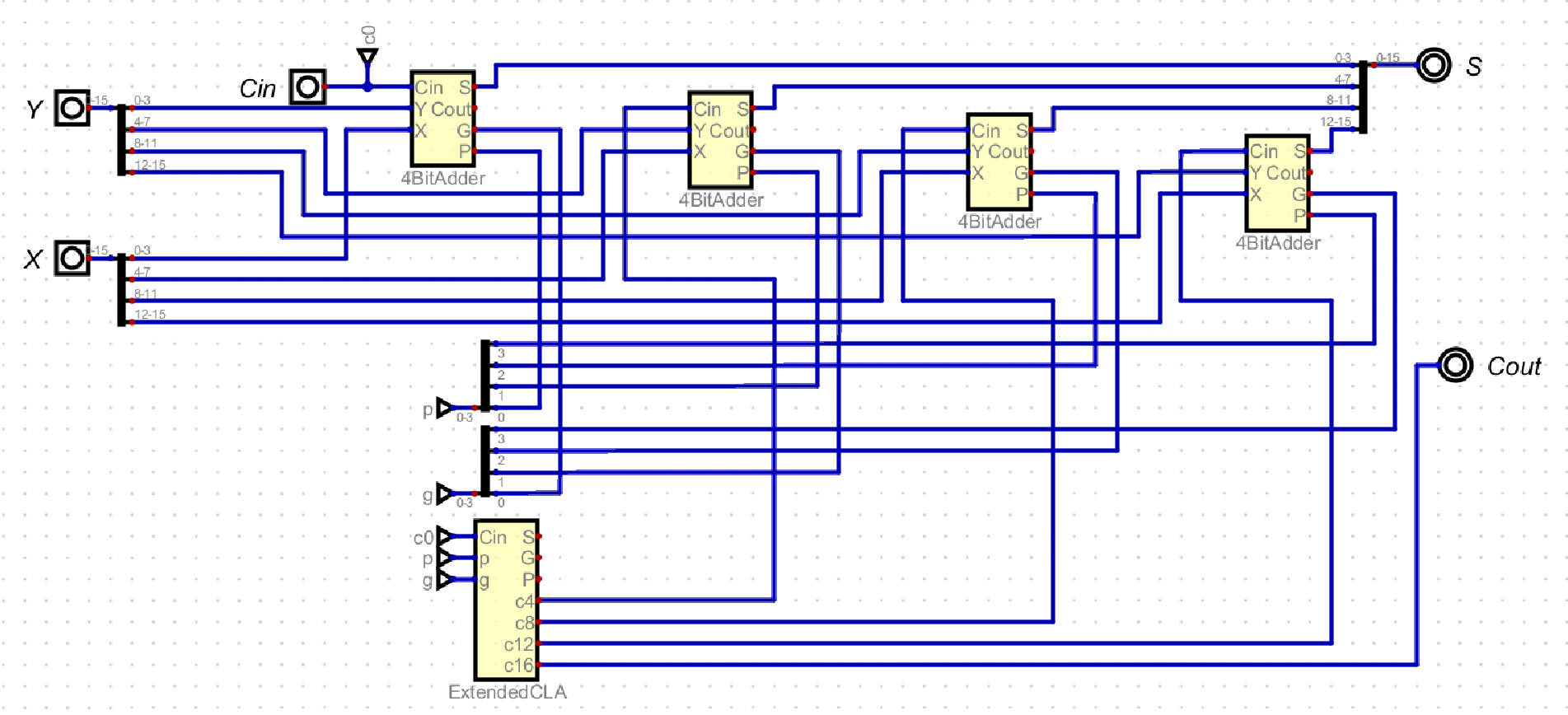
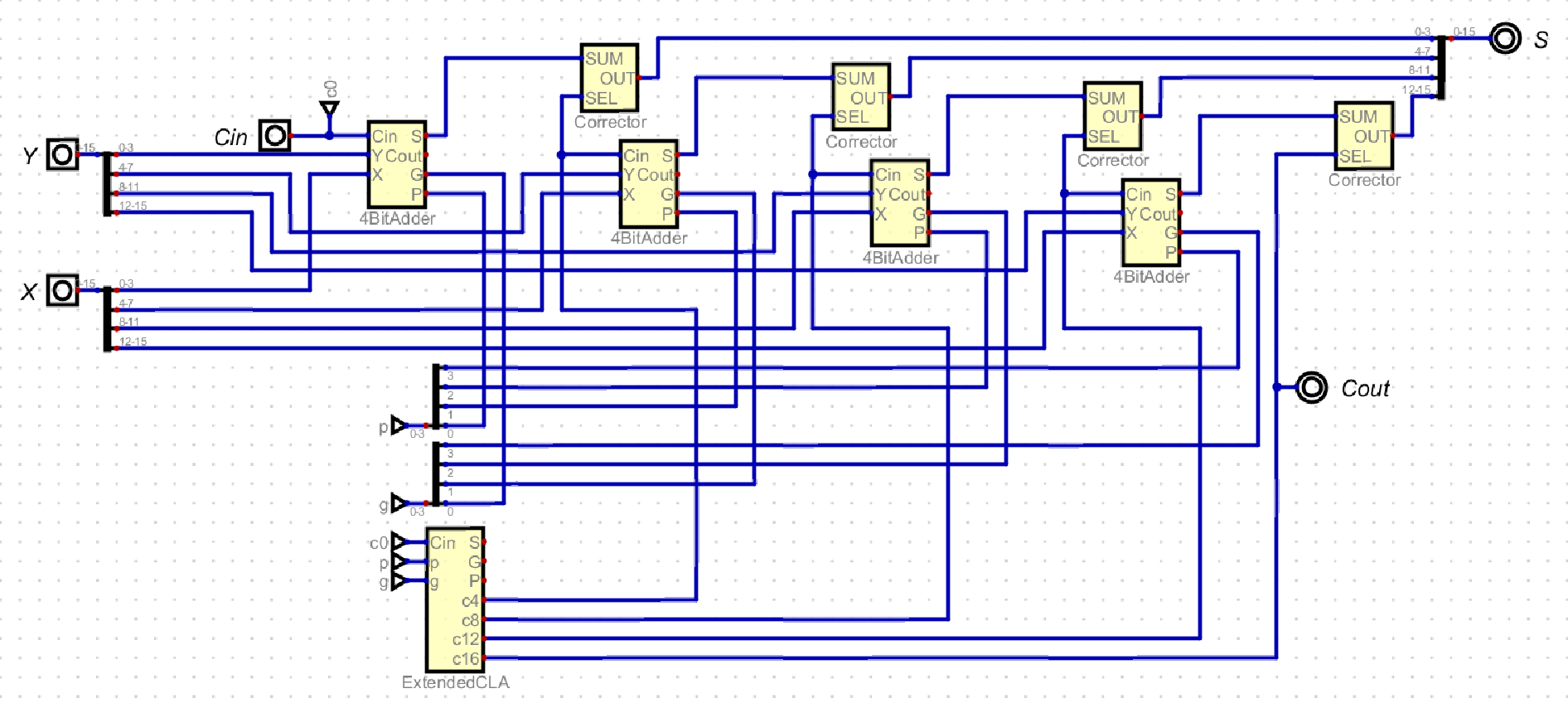
The Two Level CLA adder builds on the Single Level CLA adder by performing Carry Look-Ahead on the Ripple Carry operation results, becoming a Carry Look-Ahead full adder.
-
This implementation is derived from the standard Carry Look-Ahead full adder equations.
-
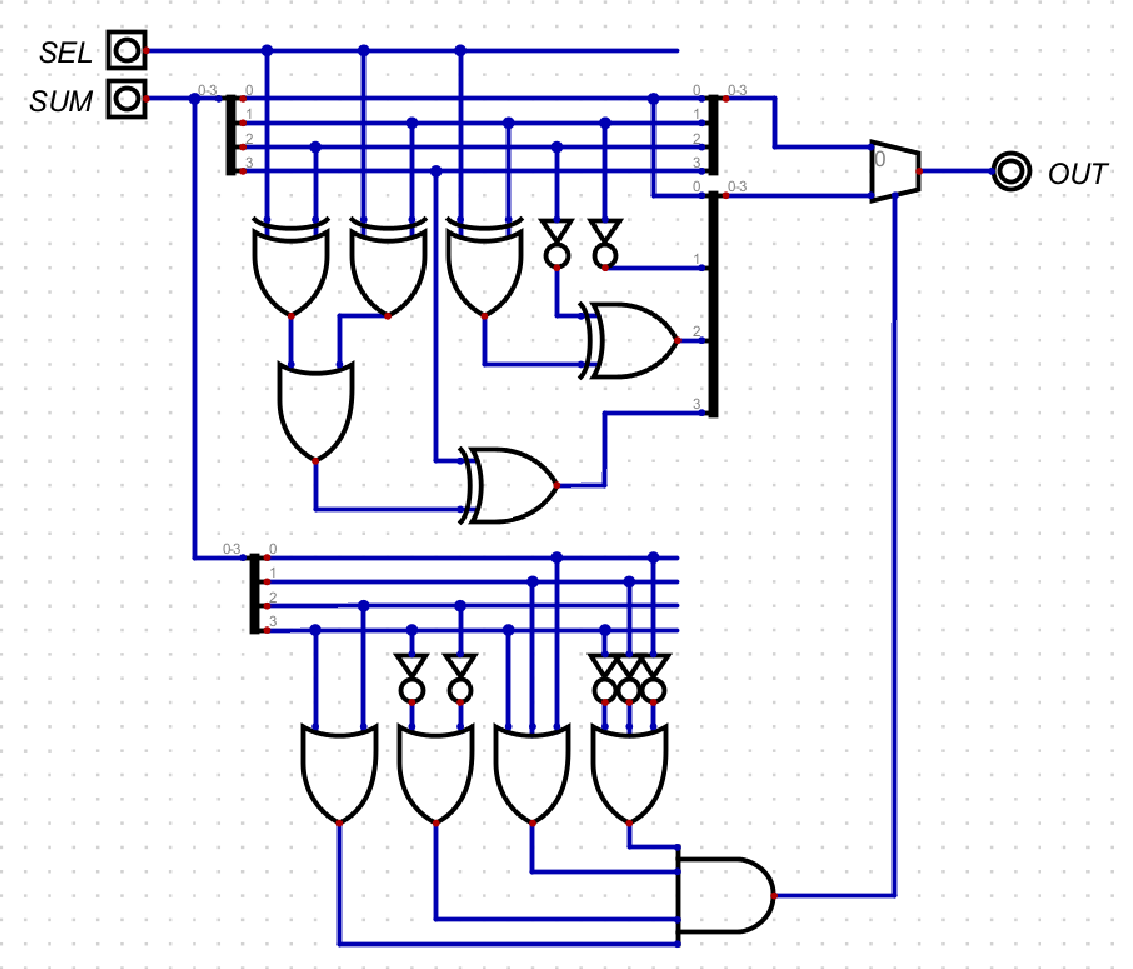
Both implementations have a variation to accomodate the 2421 weighted binary coded decimal representation.
Key Features
- 16-bit addition with carry out operations
- Uses Carry-generate and Carry-propagate functions to calculate the carryout of each sequence.
- 2421 weighted binary coded decimal representation and error detection.
Tools Used
- Digital (Digital Logic Hardware Simulator)
- (Digital GitHub Link)
Images
4 Bit Adder
Single Level CLA
Two Level CLA
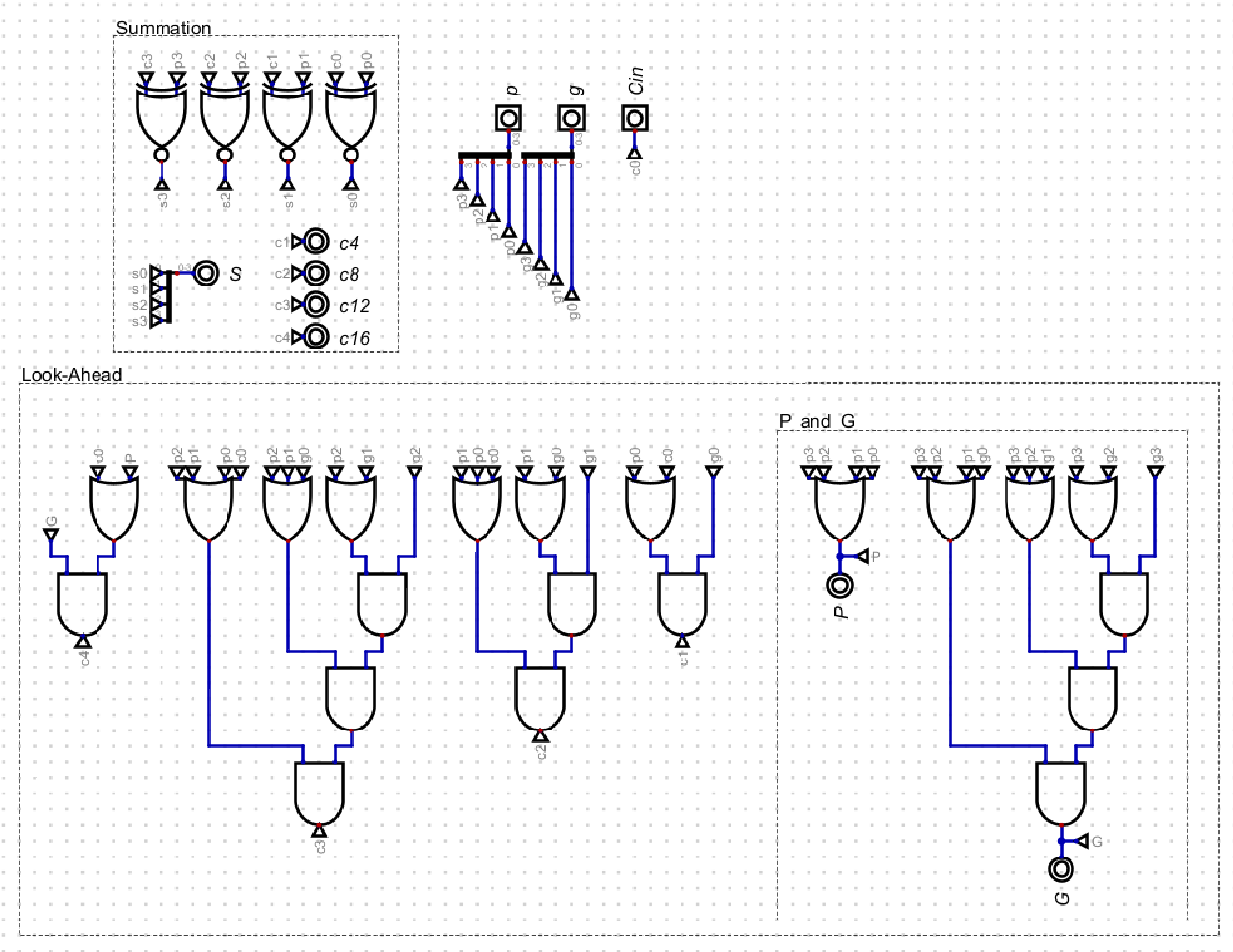
Extended CLA Module
2421 Corrector Module
2421 Single Level CLA
2421 Two Level CLA
Schema
The standard implementation of a single-bit full adder is defined as such:
Inputs: xi, yi, and ci
Outputs: si and ci+1.
An adder for numbers of n length can be created from a serial connections of single-bit full adders, detailed above. However, each subsequent bit i where 1 i n after the first bit i = 0 depends on the calculation before it being complete before the operation on the current bit can be performed. This is because the previous iteration's output carry-out is the input carry-out for the current iteration. The current calculation cannot proceed until the previous one has finished. This implementation is called the Ripple Carry Adder.
One flaw of the Ripple Carry Adder is the high delay between the input and output. A rectification of this problem is the Carry Look Ahead Adder, which enables the higher indexed carry inputs to be calculated in parallel, rather than waiting on previous carry operations to output. Two new functions are now added:
Carry-generate function:
Carry-propagate function:
These functions enable the sum function si and carry function ci+1 to be simplified to:
Expanding the carry out function for gives us:
These carry out equations give us the carry out inputs for the operations on the first four bits after the first. The carry outs have been computed in parallel. However, the calculation for requires a 5-input logical OR gate, which is time consuming and costly. We can transform the equation for to become:
Where and are defined as:
The implementation of the circuit uses an alternative but equivalent set of equations to perform the calculations. Swapping each logical OR gate with a logical AND gate and each XOR gate with XNOR gates gives us:
With these alternative equations laid out, the alternative carry functions can now be calculated:
These are the equations implemented in the 4 Bit Adder image, and four of these 4 bit adders are connected in series with each other in the Ripple Carry Adder fashion. However, in Two Level CLA, the ripple carry between the four blocks are now connected with Carry Look-Ahead, using the same equations as each 4 bit adder.