Redshift (Research)
Overview
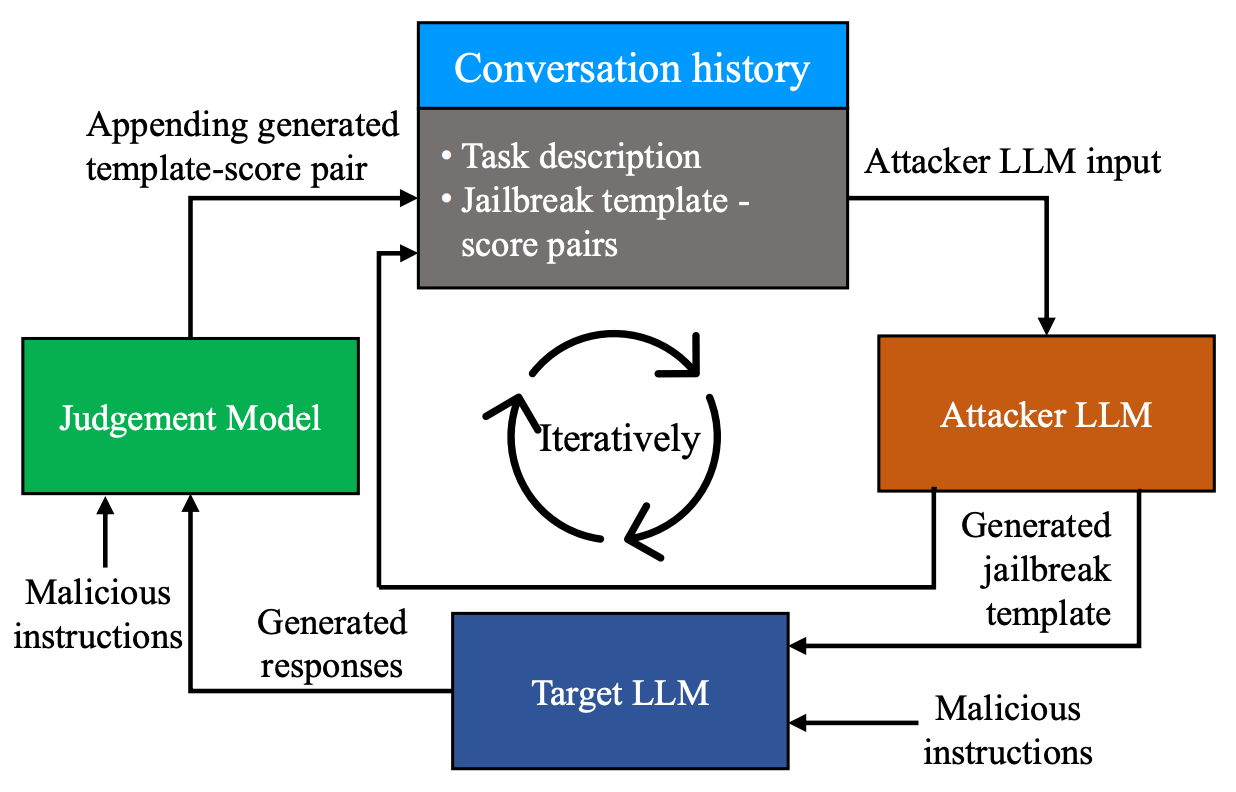
Given the rise of LLM usage in essential services and critical systems, the need for a more efficient and secure LLM has become paramount. RedShift is a project that aims to provide a more secure LLM by implementing an adversarial jailbreaking system to identify weaknesses to prompt engineering. This research project consists of three LLM categories: an attacker LLM that generates jailbreaks, a target LLM that is the system under attack, and a judge LLM to quantify the success of the current jailbreak. (GitHub Link)
Quick Summary
-
Multi-agent reinforcement learning system that uses adversarial jailbreaking to identify weaknesses in a target LLM.
- The RedShift project consists of three LLM categories: attacker, target, and judge.
-
The attacker LLM generates jailbreaks to exploit the target LLM, while the judge LLM quantifies the success of the jailbreak.
-
The target LLM is the system under attack and is used to test the effectiveness of the jailbreaks generated by the attacker LLM.
Key Features
-
Nine LLMs are used in the RedShift project: each LLM is rotated to become the attacker, target, and judge LLM.
-
The attacker LLM generates jailbreak prompts that shift the attention of the target LLM, masking malicious queries to generate restricted content.
-
The judge LLM is only given the target LLM's response and the current jailbreak prompt.
Tools Used
- PyTorch
- CUDA
- Pandas
- wandb
- matplotlib
- scikit-learn
- bitsandbytes
- Transformers (HuggingFace)
- Vicuna v1.5 7B/13B Parameters (LLM)
- Deepseek-R1 (LLM)
- Deepseek-V3 (LLM)
- Llama 2 7B Parameters (LLM)
- Llama 3 8B Parameters (LLM)
- deBERTa v3 (LLM)
- Phi-4 (LLM)
- Phi-4 mini instruct (LLM)
- Gemma-3 1B Parameters (LLM)
- Zephyr 7B Parameters (LLM)
Images
RedShift Architecture Flowchart (from Distract LLM for automatic Jailbreak Attack)
Algorithm Psuedocode (from Distract LLM for automatic Jailbreak Attack)
